

Big Data: un nuovo ecosistema digitale da cui trarre vantaggio per i processi strategici delle aziende
In questo articolo andremo ad approfondire il mondo dei Big Data, ormai diventato un fenomeno costante che sta cambiando radicalmente i processi strategici all’interno delle aziende.
Quello dei Big data è un argomento che tutt’ora è oggetto di numerosi studi ed è per questo che, vista la sua natura, non c’è ancora in letteratura una definizione specifica e universale. L’articolo avrà l’obiettivo di esplorare e analizzare le caratteristiche di questo fenomeno abbracciando più punti di vista, con l’obiettivo di offrire un valido supporto per la comprensione dei Big Data e una panoramica dei vantaggi competitivi che si possono ottenere.
Come vedremo l’esigenza di disporre di tecnologiche e metodologie per gestire il crescente volume di dati, provenienti da fonti diverse e con diversi formati, risulta essenziale all’interno dei contesti aziendali, dove è sempre più evidente anche la necessità di collegare in modo sinergico qualunque informazione per poter poi fornire un approccio visuale dei dati e creare evoluti modelli di interpretazione che necessariamente andranno adattati ai diversi mercati e business, dalla medicina al commercio, dalla finanza alle assicurazioni. È ciò che va sotto il nome di approccio “data driven”.
Nell’ambito dell’articolo, tratteremo i seguenti punti:
Il concetto di Big Data
Origine dei Big Data: brevi cenni storici
In passato la raccolta, gestione e interpretazione dei dati erano prerogative esclusive dei governi. Per esempio, nel 1943 il primo dispositivo di elaborazione di dati è stato sviluppato sul progetto del matematico britannico Alan Tuning per poter decifrare, anticipare e gestire le comunicazioni provenienti dal regime nazista durante la Seconda guerra mondiale. Tale dispositivo, chiamato Colossus, era in grado di identificare modelli tramite i messaggi ad una velocità pari a 5mila caratteri per secondo, un risultato importante per l’epoca.
Nel 1965, il governo americano invece creò uno dei primi data center per immagazzinare i dati relativi ai cittadini, anche se la tecnologia in questione necessitava fin da subito di strumenti più sofisticati per l’importante mole di dati da gestire.
Nel 1992, venne creato il Teradata DBC 1012, il primo strumento in grado di immagazzinare e memorizzare una grande mole di dati pari a 1 Terabyte.
Il primo studioso ad utilizzare il termine “Big Data” fu John R. Mashey nel 1998 durante una presentazione del suo paper intitolato “Big Data … and the Next Wave of InfraStress”. Con tale termine si iniziò a far riferimento al volume e alla crescente capacità di immagazzinare dati da analizzare, da cui poi trarre delle informazioni di ogni genere.
Nel 2005 fu anche Roger Magoulas di O’Reilly Media a diffondere il termine “Big Data” tra i suoi studi, diventando uno dei pionieri della materia.
A partire dagli anni 2000 inoltre hanno contributo alla crescita esponenziale dei dati online e della loro varietà, colossi come Facebook e Youtube ed è stato creato Spark, il primo framework open source che è da considerarsi come l’apripista per la gestione e memorizzazione immediata ed efficace dei Big Data.
Nel 2015, Bernard Marr, consulente strategico, in un suo articolo su Forbes iniziò a prevedere una continua e progressiva crescita dei dati con l’avvento della digitalizzazione, affermando anche come ogni essere umano, dal 2020 in poi, avrebbe avuto la capacità di generare 1.7 megabyte di dati al secondo e che ogni azienda, indipendentemente dal settore e dimensione, sarebbe stata capace di definire modelli di analisi dei dati per migliorare le proprie performance e profitto.
“Data is growing faster than ever before and by the year 2020, about 1.7 megabytes of new information will be created every second for every human being on the planet. By then, our accumulated digital universe of data will grow from 4.4 zettabytes today to around 44 zettabytes, or 44 trillion gigabytes.”
Inoltre, negli ultimi anni, il crescente volume dei dati ha trovato un’ulteriore spinta con lo sviluppo delle tecnologie dell’Internet of Things, che hanno portato le aziende ad avere un più facile accesso a informazioni derivanti dalle sempre più frequenti connessioni in rete tra sensori, device e sistemi. Tali flussi di informazioni, strutturati e non, possono essere utilizzati soprattutto per l’automatizzazione dei processi, rilevazione di alert, sicurezza, prevenzione del crimine, tracciamenti e analisi predittive, come ad esempio l’individuazione delle modalità di utilizzo dei device da parte dei consumatori e delle necessità di manutenzioni.
Definizione di Big Data
La maggior parte delle azioni quotidiane di ogni individuo ha la capacità di produrre dati, infatti una semplice ricerca su Google, lo scatto di una foto o un acquisto online/offline crea dati, che possono poi essere raccolti, gestiti, analizzati e interpretati.
Con l’espressione “Big Data” quindi si indica la raccolta dei dati digitali, eterogenei tra loro, che, per essere valorizzati, richiedono l’utilizzo di specifiche metodologie di gestione e modelli di analisi. Tutte queste pratiche, necessarie per l’analisi dei dati, prendono il nome di Data Mining, ossia l’insieme di tutte le tecniche utilizzate per l’estrazione delle informazioni da grandi quantità di dati.
Con la digitalizzazione, i Big Data hanno assunto un ruolo primario in tutti i settori ed è per questo che devono essere analizzati sempre con un approccio critico. A tal proposito, nel 2014 Craig Dalton e Jim Thatcher hanno introdotto in letteratura lo studio critico e sistematico dei dati “Critical Data Studies”, con l’obiettivo di mostrare come dall’analisi dei dati grezzi si possano ottenere opportunità potenzialmente infinite di conoscere i fenomeni che ci circondano[1].
A livello aziendale sono molteplici le attività che si possono ottimizzare tramite un’efficiente gestione dei Big data:
- Anticipare e comprendere i market trend digitali e aumentare il valore della propria Brand Perception.
- Creare un ideale Digital Personas/Buyer così da conoscere i profili standard dei consumatori e i fattori che spingono all’acquisto.
- Segmentare e targettizzare i cluster di consumatori, per poter indirizzare comunicazioni aziendali verso un target specifico.
- Definire strategie predittive in grado di effettuare simulazioni di diversi scenari economici, così da poter ottimizzare le future strategie di business e creare nuovi modelli di business.
La normativa
Come già accennato, ad oggi, non esiste in letteratura una definizione specifica e universalmente accettata del temine Big Data. Questo aspetto si riflette anche sul piano legislativo dove le attuali norme non menzionano in modo chiaro tale termine, lasciando presupporre la necessità di una normativa specifica.
Tuttavia, in risposta a questo “vuoto” legislativo, attualmente nei paesi dell’Unione Europea vige il Regolamento generale per la protezione dei dati personali n. 2016/679 (GDPR), che è stato pubblicato sulla Gazzetta Ufficiale europea il 4 maggio 2016 ed ha trovato applicazione a partire dal 25 maggio 2018.
Il GDPR ha come obiettivo quello di attuare una protezione dei diritti e delle libertà delle persone fisiche, in relazione al trattamento dei dati di carattere personale, mirando ad una tutela elevata e coerente in tutti gli Stati membri. A riguardo, il Regolamento si pone come garante per il diritto di trasparenza, assicurando un controllo coerente sui dati personali, sanzioni uguali in tutti gli Stati membri e una cooperazione sinergica tra le varie Autorità di controllo. A tutela dei soggetti interessati, il Regolamento prevede anche l’obbligo di consenso esplicito al trattamento dei dati personali, il diritto alla rettifica dei dati e l’opposizione all’utilizzo dei dati stessi.
In definitiva, la normativa ha l’obiettivo primario di regolamentare il più possibile il crescente utilizzo dei dati, cercando di stare al passo con il progresso tecnologico e culturale tipico dell’ecosistema digitale in cui operiamo.
Inoltre, per un’adeguata applicazione di tale Regolamento sono anche intervenute le autorità nazionali per la protezione dei dati (“APD”) che, essendo entità indipendenti a tutela dei diritti fondamentali e del trattamento dei dati personali, concordano che i principi legislativi per la protezione dei dati (come equità, proporzionalità, liceità e finalità) possono essere applicati anche alle regolamentazioni che gestiscono il fenomeno dei Big Data.
Le classificazioni delle fonti dei Big Data
La presenza dei dati, nel contesto attuale, è così diffusa e pervasiva che, come accennato, la varietà di formati e caratteristiche dei Big Data risulta potenzialmente infinita. Tuttavia, in letteratura, per una miglior individuazione della sorgente, i diversi dati sono spesso classificati in:
- Human generated
- Machine generated
- Business generated
Human Generated
Nella categoria “Human generated” vengono considerati tutti i dati provenienti da quelle fonti in cui l’utente ha un ruolo primario nella generazione dell’informazione, come le piattaforme di social network, blogging, siti di recensioni o portali di e-commerce.
Machine Generated
I dati “Machine generated” invece fanno riferimento a tutti i dati provenienti da quelle sorgenti che in automatico possono generare varie tipologie di dati, quali sensori GPS, dispositivi IoT, piattaforme di trading per i mercati finanziari, dispositivi biomedicali/industriali o smartphone.
Business Generated
Infine, per i dati “Business generated” facciamo riferimento a tutti i dati (human e machine) che sono invece generati all’interno di un’azienda grazie alla sua attività e strategia data-driven e archiviati in database relazionali specifici per ogni dipartimento aziendale.
Modelli e approcci per la gestione dei Big Data
Dal modello delle 3V a quello delle 5V
Nel 2001, Doug Laney (ex vice presidente e Service Director di Meta Group), durante un proprio studio sul fenomeno dei Big Data, elaborò un nuovo modello in grado di definire i dati provenienti da più fonti eterogenee e di adattarsi all’evoluzione delle tecnologie.
Tale paradigma prese il nome di “Modello delle 3V”, ossia 3 concetti in grado di classificare e gestire i dati: Volume, Velocità e Varietà. Col passare degli anni e con l’evoluzione del fenomeno tale modello è stato integrato con altri due elementi in grado di definire e interpretare ancor di più nello specifico le caratteristiche di ogni dato (Veridicità e Valore).
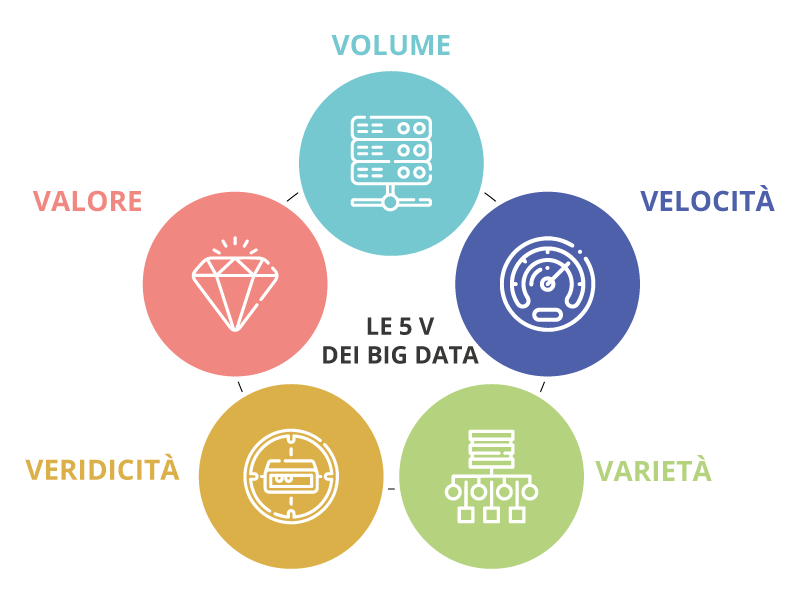
Volume
Uno dei primi elementi considerati dal paradigma di D. Laney è quello relativo al volume dei dati. Infatti, in questo caso si fa riferimento all’ingente massa di dati e informazioni che ormai si possono raccogliere tramite le nuove tecnologie e che riguardano molte attività della nostra vita quotidiana. Il volume dei dati è in continua ed esponenziale crescita, infatti si stima che la quantità di dati creati nei prossimi tre anni sarà superiore a quella generata negli ultimi 30 anni e che il nuovo ecosistema digitale sarà in grado di produrre, nei prossimi cinque anni, una quantità di dati maggiore di tre volte rispetto ai cinque anni precedenti[2].
Proprio questa importante crescita pone il dubbio sulla soglia da stabilire oltre il quale si può parlare di Big Data, soglia che è stata fissata, ad oggi, dai 50 Terabyte in poi.
I
rischi legati al volume dei dati, oltre alla gestione, sono anche riconducibili
alla qualità e diversità delle informazioni immagazzinate, poiché è necessario
correlare tutte le diverse tipologie di dati, strutturati e non.
Velocità
Una delle caratteristiche più significative per i dati è la velocità di quest’ultimi di generarsi e di essere acquisiti. Infatti, dato l’elevato volume, risulta sempre più difficile e costoso dotarsi di strumenti in grado sia di raccogliere i dati in tempo reale ma anche di analizzarli e metterli a disposizione nell’immediato. Per le aziende risulta essenziale questo fattore per acquisire un vantaggio competitivo, dato che aumentare la velocità di analisi e destrutturare i volumi di dati ricevuti può creare indicatori strategici rilevanti per il business.
Varietà
Con il termine varietà si fa riferimento alle differenti caratteristiche di ogni singolo dato disponibile, reperibile da fonti eterogenee. Infatti, in un ecosistema digitale, i dati possono essere strutturati e non strutturati, richiedendo così diversi livelli di analisi e interpretazione. Per questo motivo risulta necessario dotarsi di indicatori semplici ma flessibili e rapidi, in grado di recepire ogni singola tipologia di dati ed interpretarli a seconda delle loro differenti caratteristiche.
“More isn’t just more. More is different.”–Chris Anderson, Wired, 2008
Veridicità
Quando si parla di Big Data, i pilastri imprescindibili per dar vita ad un’analisi e una gestione dei dati attendibile sono sicuramente la qualità e l’integrità delle informazioni che si riescono ad ottenere. Infatti, non sempre i dati immagazzinati possono risultare veritieri ed attendibili e quindi possono andare a contaminare e inficiare le nostre analisi. Per le aziende risulta necessario applicare metodologie di Data Governance in grado di “validare” ogni singolo dato, in modo da poter effettuare analisi accurate su cui basare decisioni strategiche di breve e medio-lungo periodo.
Valore
Analizzare i dati e le informazioni che producono conoscenza, significa in primis anche valutare le relazioni che intercorrono tra essi. Visto il crescente volume dei dati, risulta sempre più essenziale analizzare i dati ricevuti e avere poi la capacità di rilevare solo le informazioni di valore, utili per determinate scelte strategiche in correlazione al settore di riferimento. Per poter attuare questo processo e far in modo che i Big Data possano essere trasformati in informazioni utili, risulta fondamentale l’utilizzo di strumenti avanzati di Analytics e di Data Quality, fondamentali per estrarre valore dai dati e prendere decisioni più tempestive e consapevoli.
Data Value Chain nei modelli di gestione dei Big Data
Ogni paradigma legato ai Big Data si basa su una specifica catena del valore, che è composta da attori e fattori diversi che possono essere o meno integrati in un unico centro di analisi (identificabile o come un’impresa o un centro di ricerca).
In linea di massima la catena del valore dei Big Data è composta da quattro fasi conseguenziali:

Generazione
La catena del valore ha come inizio la fase di generazione dei dati, intesa come l’acquisizione delle informazioni in formato puramente digitale. A sua volta la generazione può essere suddivisa in acquisizione e consenso. L’acquisizione consiste nel venire in possesso dei dati da una fonte che può essere interna o esterna e può essere generata o da un individuo (persona fisica) oppure da uno strumento tecnologico. La seconda fase invece prevede la necessità di ottenere il consenso per la cessione dei dati da parte di chi ne possiede la proprietà, in risposta alle legislazioni vigenti a tutela del trattamento dei dati.
Raccolta
In questa fase i dati devono essere necessariamente trasmessi dal punto di generazione a quello di archiviazione tramite l’utilizzo di un’infrastruttura tecnologica, per poi essere integrati con altri dati provenienti da fonti diverse e infine inseriti in un processo di convalida (Data Quality) al fine di garantire la correttezza e l’integrità dei dati stessi.
Analytics
Nella fase degli Analytics inizia la fase di processamento, fondamentale per trasformare i dati provenienti dai vari database aziendali, in informazioni tramite processi di data mining. Una volta ottenuti questi output in questa fase c’è un secondo step che riguarda la fase pura di analisi del dato lavorato.
Scambio
L’ultima fase della catena del valore consiste nello scambio dei dati lavorati, partendo dallo step del packaging fino ad arrivare a quello successivo della vendita/utilizzo. Per packaging intendiamo l’impacchettamento e la preparazione dei dati all’utilizzo, come la creazione di reportistica e la definizione di uno storytelling grafico dei dati così da renderli fruibili per le decisioni strategiche.
La fase della commercializzazione/utilizzo prevede nello specifico tre casistiche:
- utilizzo interno dei dati lavorati (forecast commerciali, …)
- vendita a terzi dei dati (dataset per successive elaborazioni)
- vendita a terzi di servizi (information provider, targeting, posizionamento competitor…).
Approcci diversi per la gestione dei dati: Big Data e Business Intelligence
La crescente maturità del fenomeno dei Big Data ha evidenziato come, molto spesso, questo concetto possa essere utilizzato, in modo fuorviante, in correlazione al tema della Business Intelligence.
In realtà questi due argomenti sono molto differenti tra loro in termini di dati esaminati e di utilizzo. Infatti, la Business Intelligence utilizza la statistica descrittiva caratterizzata da dati ad alta intensità di informazione, con dataset limitati e modelli semplici al fine di rilevare tendenze e trend di mercato.
I Big Data invece si basano su una statistica inferenziale, facendo riferimento a dati con una bassa densità di informazione e utilizzando modelli predittivi complessi ed eterogenei, con l’obiettivo di poter rilevare correlazioni e dipendenze tra i dati (regressioni, relazioni non lineari, ed effetti causali) e garantire accurate previsioni e tendenze future.
Applicazioni e benefici dei Big Data
I modelli di analisi dei Big Data
Vista la loro natura e varietà, possiamo affermare come un patrimonio di dati grezzi non garantisce un valore per imprese e aziende, ma lo assume tramite l’utilizzo di algoritmi predittivi e logiche di correlazione, mettendo a punto accurate tecniche di profilazione o analisi previsionali dai dati lavorati.
A tal proposito, per poter meglio estrarre, gestire e analizzare i dati in funzione degli obiettivi strategici, è possibile distinguere specifici modelli di analisi per una migliore gestione dei Big Data:
- Descriptive Analytics: metodologia che permette di definire processi aziendali utilizzando i dati in maniera interattiva, con l’obiettivo di mostrare una panoramica della situazione attuale o passata dei processi aziendali.
- Predictive Analytics: metodo basato su tecniche matematiche con lo scopo di strutturare analisi predittive tramite le informazioni contenute nei dati.
- Prescriptive Analytics: metodo analitico in cui vengono definite le motivazioni delle soluzioni operative e strategiche future tramite i risultati provenienti dalle analisidescrittive e predittive sopra illustrate.
- Automated Analytics: strumenti in grado di applicare in maniera automatica azioni definite e condivise da regole e processi di analisi dei dati.
Le tipologie di strumenti disponibili sul mercato
Ormai è evidente la necessita di dotarsi di strumenti avanzati per la gestione dei Big Data, visti gli innumerevoli vantaggi che questi possono offrire a qualsiasi settore aziendale. Tuttavia, considerando la complessità del fenomeno, per molte aziende potrebbe essere complicato individuare la migliore tecnologia di gestione e analisi dei Big Data presente sul mercato, che meglio si adatti al settore specifico, progetto di riferimento ed esigenze di business.
Sul mercato ad oggi sono disponibili piattaforme avanzate che sono in grado di analizzare un grande volume di dati ma anche di raccoglierli e categorizzarli. Infatti, risulta fondamentale dotarsi di tecnologie che siano in grado non solo di trarre valore dai dati ma anche di strutturarli e ordinarli, così da poter effettuare analisi in tempi brevi ma con un elevato livello di qualità. In linea generale gli strumenti disponibili sul mercato possono essere raggruppati in tre grandi macroaree di offerta[3]:
- Aggregatori: Strumenti che hanno come peculiarità quella di raccogliere e organizzare i dati provenienti da fonti eterogenee. In questa categoria rientrano tutti gli strumenti che raccolgono dati da diverse fonti tenendo conto anche di più archi temporali. Tali dati vengono poi strutturati, integrati e ordinati in modo da poter essere poi utilizzati a supporto dei processi decisionali. Questa tipologia di strumenti viene utilizzata soprattutto da quelle aziende che, o per obiettivo strategico o per necessità dovute a operazioni di M&A, diversificano il proprio business, andando di conseguenza gestire e ordinare varie tipologie di dati e fonti diverse.
- Arricchitori: Questa categoria comprende gli strumenti che pre-elaborano i dati al fine di estrapolare informazioni specifiche in linea con le necessità aziendali. Possiamo includere in questa macroarea i software di “Sentiment Analysis” che analizzano i contenuti e i linguaggi (opinioni, interessi, preferenze) partendo da documenti e testi presenti nel web, da cui trarre informazioni circa i bisogni di una possibile nicchia di clientela. Poi possiamo citare anche gli strumenti di CRM e Customer Analytics che hanno come obiettivo quello di gestire e interpretare i dati relativi alla clientela. In linea generale questi strumenti vengono utilizzati per segmentare il mercato, profilare la clientela così da poter personalizzare il più possibile la strategia aziendale e rivolgersi ad un target qualificato.
- Modellatori: In questa categoria rientrano tutti gli strumenti che hanno come finalità quella di creare modelli di previsione tramite l’utilizzo di algoritmi che evidenziano schemi e correlazioni tra i dati. Possiamo citare gli strumenti di Predictive Analytics e Prescriptive Analytics e tutti quei tool che si servono della tecnologia di Intelligenza Artificiale come il Machine Learning.
Opportunità e vantaggi: Big Data vs Thick Data
Per poter sfruttare al meglio il potere dei dati e le loro potenzialità è necessario renderli accessibili a tutti i reparti dell’impresa a prescindere dalle funzioni aziendali, in maniera trasversale e completa tramite una struttura omogenea ma adattabile ad ogni esigenza dell’organizzazione. In questo modo è possibile utilizzarli lungo tutta la catena del valore, ottimizzando non solo i processi di fornitura, produzione e marketing ma anche quelli legati ai servizi post-vendita.
Tuttavia, nonostante il potenziale infinito dei Big Data, l’analisi interpretativa dei dati deve necessariamente seguire un approccio non solo puramente quantitativo ma anche qualitativo, puntando anche a fattori esterni ai dati disponibili. Infatti, le potenti piattaforme dei Big Data hanno creato la convinzione che bastasse possedere una gran mole di dati da mettere in relazione per conoscere, con certezza statistica, tutte le informazioni necessarie relative a clienti o fenomeni futuri. Invece, negli ultimi anni, si fa sempre più spazio il concetto dei Thick Data, come fenomeno a completamento ed integrazione dei Big Data.
“I thick data colmano le lacune nell’analisi dei big data”[4] – Mary Shacklett
In letteratura, i Thick Data sono da intendersi come tutti quei dati qualitativi collegati ai pareri delle persone, ai loro comportamenti e alle loro relazioni strettamente connesse alla sfera emozionale. Da qui nasce l’opportunità di relazionare i Big Data non solo a schemi statistici e quantitativi ma anche ai modelli comportamentali riconducibili a ciascun individuo.
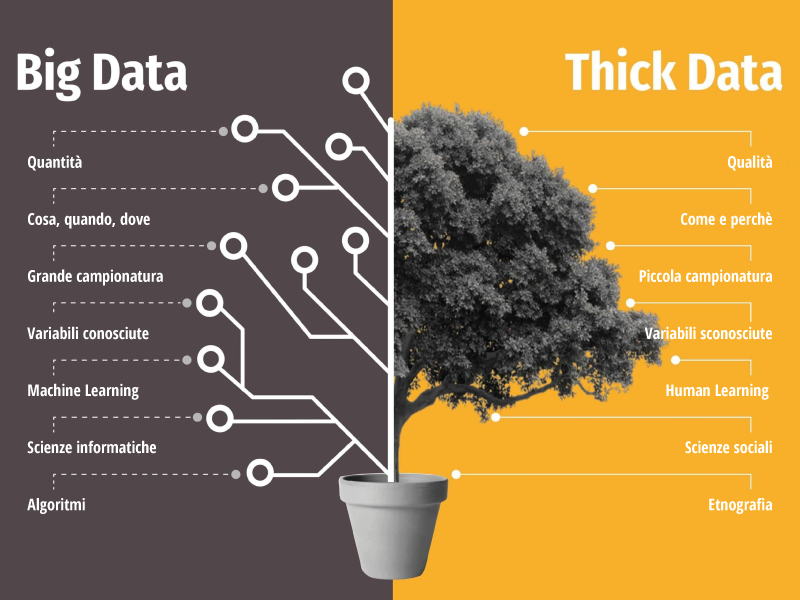
La correlazione e l’integrazione tra queste due tipologie di analisi fornisce quindi alle aziende un contesto molto più completo. Infatti, Big e Thick Data aiutano i Brand a conoscere tutte le sfumature che guidano i comportamenti dei clienti e prospect, poiché in questo modo ci si focalizza sulle informazioni “nascoste” nei numeri senza però trascurare la sfera emozionale che è parte fondamentale di ogni processo di acquisto.
I Thick Data, basandosi sull’apprendimento umano, fanno emergere le peculiarità del contesto sociale, mentre i Big Data, forte dell’automazione dell’apprendimento, evidenziano gli approfondimenti su una moltitudine di elementi, favorendo l’aspetto quantitativo.
In definitiva i Thick Data non devono essere considerati come l’antitesi dei Big Data ma come il loro naturale elemento complementare. Infatti, le aziende, solamente integrando queste tipologie di dati, potranno ottenere un vantaggio competitivo potenzialmente infinito, ossia creare una simbiosi tra qualità e quantità, anticipando trend di mercato ed eventi futuri non trascurando la sfera comportamentale.
“Thick data grounds our business questions in human questions” [5] – Tricia Wang
In conclusione, possiamo affermare come ormai il fenomeno
dei Big Data sia in piena espansione, ma è altrettanto chiaro di come sarà difficile
prevedere gli sviluppi futuri delle varie tecnologie. Sicuramente le organizzazioni
aziendali, grazie ad una giusta applicazione dei Big Data, potranno raggiungere
nel lungo periodo un’efficienza operativa costante, una riduzione dei
costi e allo stesso tempo un miglioramento sia della produzione che dei
rapporti con i clienti e fornitori. Tuttavia, questi miglioramenti,
dati anche i continui aggiornamenti in letteratura, richiederanno investimenti
in tecnologie e know-how altamente specializzato, ma solo così si potrà avere
una redditività nel lungo periodo, difficilmente replicabile dai competitors.
[1] “What does a critical data studies look like, and why do we care? Seven points for a critical approach to ‘big data”, Craig Dalton and Jim Thatcher, Society and Space, 2014
[2] “IDC’s Global DataSphere Forecast Shows Continued Steady Growth in the Creation and Consumption of Data”, International Data Corporation (IDC), 2020
[3] “Digital report”, Forrester Research, 2015
[4] Tech Republic, Mary Shacklett, 6 gennaio 2015
[5] “The human insights missing from Big Data”, TEDx Cambridge, Tricia Wang, 2016